Generating Mixtapes with Machine Learning
One habit of mine is listening to the same songs so much they become less enjoyable, in spite of a world of other related music out there to enjoy as well. This problem leads to the project’s first goal; mapping a music collection so a recommendation system can be built from it, which is is complemented by a second goal; producing visual media using album artwork in the collection. The minimum viable product is an application to recommend music while involving generative imagery in the process. Both sides are developed separately before being connected which leaves the format of the final outcome up for some experimentation.
Context
Ideas for music recommendation come from proprietary Spotify-like services which benefit from big data they collect and train machine learning systems with. My main point of reference to achieve the goal is Christian Peccei’s ‘Mapping Your Music Collection’ blog (link here). The steps in a nutshell are:
- Analyse musical features
- Reduce the dimensionality of the extracted information
- Use k-nearest neighbors to recommend songs most similar in feature space.
Adam Geitgey’s 8-bit pixel art blog (link here) is what the generative image side of this project is based on. He uses an unsupervised machine learning algorithm which puts two deep neural networks against each other. Some other generative models I looked at are discussed here: OpenAI blog.
Implementation
Album covers that were automatically de-duplicated by fdupes
Machine learning starts with data, so the first step in this project was to organise music and album covers into folders. An issue here is duplicates as they could skew the music recommendation if left unaccounted for, so my instinct was to verify there weren’t any. I ran the command-line program fdupes which compares file hashes and located 374 duplicate audio tracks (just over 2%) which were removed. Many album covers are embedded in MP3 files which I extracted using eyeD3. De-duplicating the folder of album covers found and removed 7204 (over 80%) items. Images were standardised into 128x128 PNG format using ImageMagick.
Analysing Musical Features for Similarity
Good features to compare musical similarity in a robust way are high-level metrics. I tried a musical analysis system called AcousticBrainz which quantifies music in terms such as ‘danceability,’ but the output was formatted in a way that meant each song can have a different sized feature vector containing different types of information (character strings and floating point numbers). So to ease the next stages I researched for a simpler music analysis library and came across RP_extract which is a library for “music similarity, classification and recommendation.” With it I produced three CSV files with different categories of musical features for every song in the collection. Having sets of different audio features meant they could be judged later on by comparing the music they recommend for the same song.
Generating Images from Album Covers
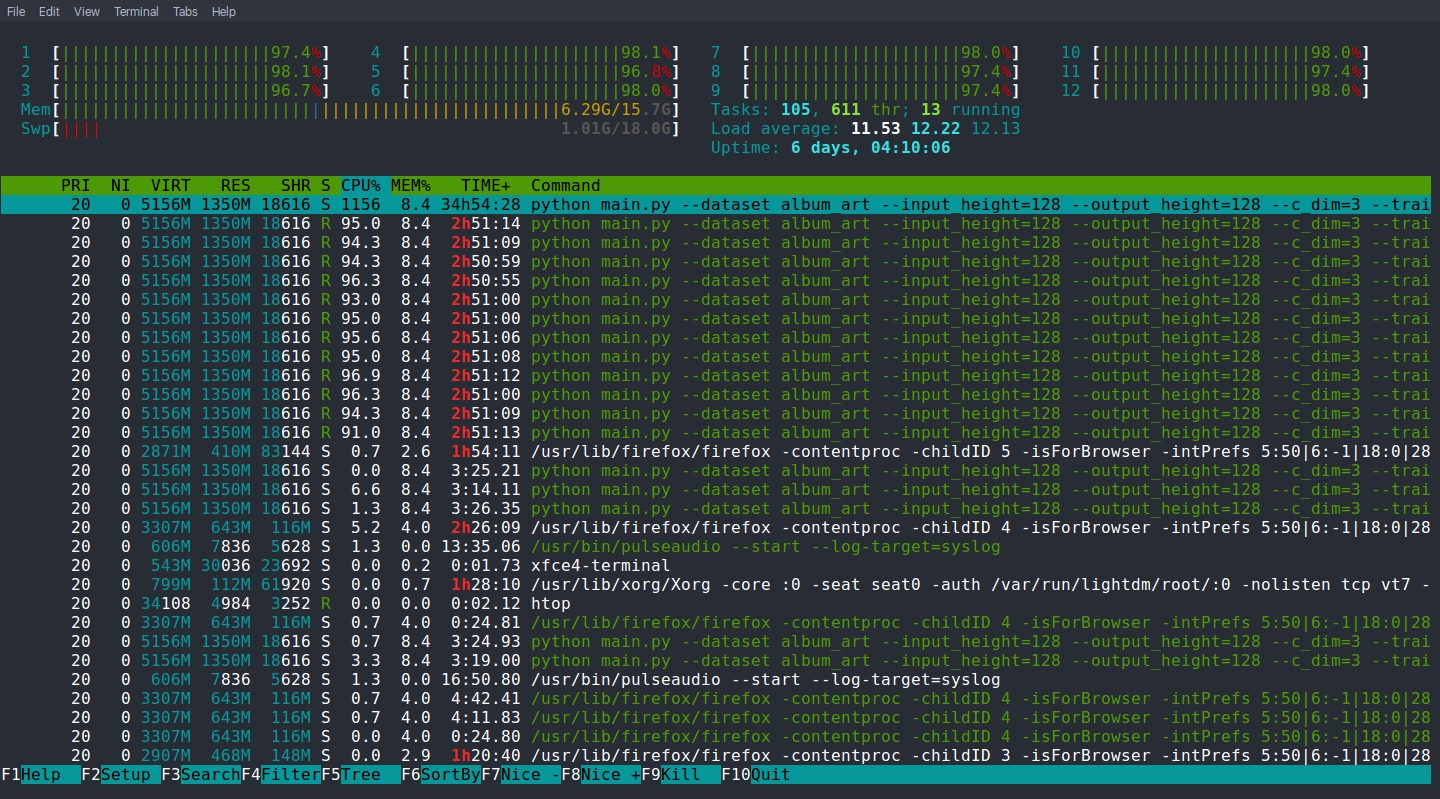
CPU and RAM usage of Tensorflow DCGAN training on my album covers (the top 12 processes!)
Generative images were produced by training a model on the album covers. I ran a Tensorflow implementation of Deep Convolutional Generative Adversarial Networks which produced very empty images until several epochs of training had taken place. At that point it started producing images with abstract-looking compositions that developed into more defined shapes, sometimes resembling human figures and even text. After several days of training the images seemed to stop developing so I exited and collected over 30,000 covers it had generated. In the spirit of ‘truth to material’ (link) I decided to include all of them, even the earliest, through the second level of analysis taking some inspiration from Jeff Thompson’s blog (link here). The second level of analysis was dominant colour extraction using a Python library I found called Haishoku, which I used to save each image’s file name with 7 dominant colours in RGB and their percentage into a single text file.

Sample of 1,296 generated images with 7 dominant colour features reduced into 2D then fitted to a grid
The curse of dimensionality describes the difficulty of analysing high dimensional data, and it was very relevant considering 1,668 features were extracted from every song and 32 for every generated image. Using t-SNE (in the form of ofxTSNEParallel) I reduced all audio and visual features into two dimensions, and repeated the process using a range of parameters suggested here: link.
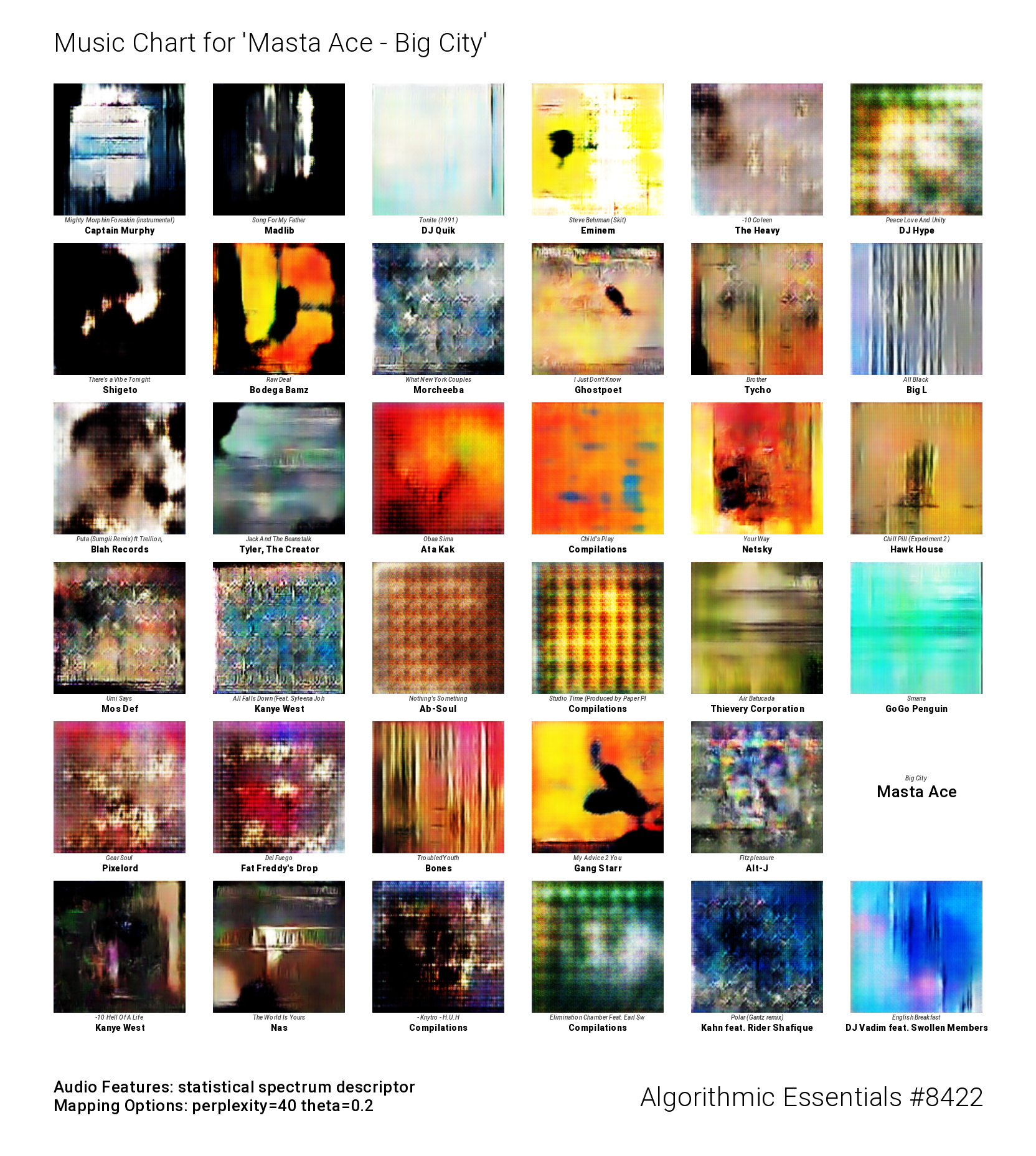
An example output saved by the final application
The image above shows what the final application produces. It chooses a random song (this time by by Masta Ace) and generates a playlist using the closest other songs in t-SNE space, displaying them in a chart together with generated images. In this sense the openFrameworks application brings everything together. It works by importing string lists and analysis CSVs at runtime (taking advantage of ofxCsv to parse t-SNE output) and maps any given subsets of music and imagery from continuous 2D space into regular grids using ofxAssignment.
Evaluation
All in all, the final application satisfies the goal of supporting music recommendation within my collection. In its current state it enables over ten unique recommended playlists to be produced seamlessly from a single ‘seed’ song. Each of those playlists is based on different sets of musical features and t-SNE parameters which make useful comparisons considering this is my first serious attempt at musical analysis and machine learning. I presented some of the playlists to a sample of Goldsmiths students and one said “there are definitely some influences there.”
I am skeptical that the recommendations are informed by musical qualities as much as they are by my own tastes. For example a playlist I seeded from the duo Madvillain included songs from other stage names of the same artist (MF DOOM, Viktor Vaughn and King Geedorah) which is either proof that the system works or proof that I have his discography. Both may be true however I haven’t yet picked a set of musical features and t-SNE parameters in the application that consistently gives me recommendations I prefer.
The second goal of generating images was achieved 30,000 times over - granted thousands appear to be little more than monochrome noise. Observing generated images gradually develop was fascinating when they started to show text-like inscriptions and human-like figures. Actually I think the images are so abstract that they are susceptible to inducing pareidolia and confirmation bias; we see patterns that may not really exist. Alec Radford of OpenAI trained a GAN on 700,000 album covers and produced results seen here: link. When comparing the images his model generated they are clearer and much more developed.
A frustrating challenge for me in this project was sorting all the data - it required interoperating bash with Python and various file formats. Sometimes I ended up bodging solutions together, for different problems found online, which was time consuming and involved some trial and error to get right.
I would like to improve the user experience of the openFrameworks application in the future. One possibility is allowing the user to click any of the recommended songs to select the next playlist seed. Another improvement would be a search feature.
Something that went beyond this project’s scope is conditional image generation (examples here and here). Using beets (link here) to fetch full and accurate music metadata, I think it may be possible to then condition image generation for playlists that the model thinks will fit the music best.
Instructions
Download and extract this: link find password with submission
Copy CML_mixtape-generator into the openFrameworks apps folder
Install ofxCsv and ofxAssignment (links below) in the openFrameworks addons folder
Build the project with openFrameworks’ project generator
Run the application (you may have to change the path to images from what I used in development)
Codebase
This project is based on my own music collection but with the exception of kNN it was realised with thanks to the third-party projects and algorithms I used:
openFrameworks 0.9.8 http://openframeworks.cc/
Taehoon Kim’s DCGAN implementation https://github.com/carpedm20/DCGAN-tensorflow
ofxTSNEParallel https://github.com/bakercp/ofxTSNEParallel
RP_extract https://github.com/tuwien-musicir/rp_extract
ofxAssignment https://github.com/kylemcdonald/ofxAssignment
Haishoku colour palette extraction https://github.com/LanceGin/haishoku
This post is for Data and Machine Learning for Creative Practice (IS53055A)