Visualising Machine Learning Agorithms
Week Four:
- Q&A question on learn.gold (forum link)
- Online quiz on learn.gold
- Wekinator Assignment 4 on learn.gold (and here)
Reflection:
An interesting question asks what classes k-nearest neighbors algorithm as ‘machine learning’. It can be argued that it is so simple in comparison to neural networks and other machine learning algorithms that it just doesn’t fit. There is no training involved which is another way it stands out compared to most other solutions. On the other hand it gives excellent results in many cases so the fact it can be understood easily doesn’t take away from how capable it is.
This week we experimented with classification and considered factors like expressivity and processing speed with regards to ML in creative practice. k-NN is often the first method to be considered because of how simply it works; it categorises new inputs based on the classes of the k closest examples in the feature space. The screenshot below illustrates kNN decision boundaries generated very quickly because a) kNN has no training involved unlike AdaBoost + most other approaches and b) the problem had very few low dimension examples to calculate euclidean distance to. The next image shows support vector machines (SVM) classification in a scenario that kNN would suffer in; many examples with lots of noise. Although kNN doesn’t cope well with noise it can hypothetically generate the same complex boundaries as SVM, it just needs good training data and a high value for k to smoothen the boundary edges. In creative contexts I think controlling parameters is useful as an alternative to the tedious process of refining training data, however parameters can also have implications on speed. For example the ‘RBF’ kernel option used in the last image below took a long time to generate boundaries that look like natural land masses from random data. So, although it might produce amazing generative terrain in a game, the compute-time might make it unpractical.
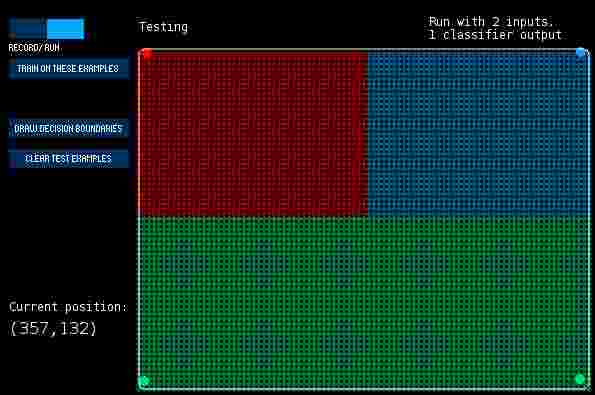
Above: kNN decision boundaries (the four points in the corners are the training examples)

Above: Decision boundaries made from quite random data by SVM

Above: Decision boundaries made by SVM with the RBF kernel
For Data and Machine Learning for Creative Practice (IS53055A)